
[starbox id=”1” theme=”business”]
İstatistik ve metot ile ilgili yazı dizimize devam ederken özellikle sayısal verinin düzgün bildirimi ve genel bir tekrarı yönünde oldukça fazla talep gelmeye başladı. Her ne kadar istatistikden ziyade metodoloji ağırlıklı bir yazı dizisi şeklinde tasarlamış olsam da biraz “kenarda dursun” mantığıyla sayısal verilerin sunumu kısımlarını içeren temel istatistiğin girizgah kısımlarından biraz bahsedelim.
Sayısal verilerin sunumu makale yazımının en önemli kısımlarından biridir. Kelimelerle aranız ne kadar iyi olursa olsun, sayısal verileri genel geçer kurallara uygun şekilde yazmadığınız takdirde tam bir acemi gibi görünmeniz ve makalenize olan güveni tamamen kaybetmeniz gayet mümkündür. Forrow 1992 yılında yayınladığı makalesinde tanımlayıcı istatistiklerden biri yerine diğerini seçmenin makaleyi okuyan hekimlerin klinik kararlarını etkilediğini belirlemiş. Forrow’u haklı bulsam da, yanlış tanımlayıcı istatistik ve eksik bildirim şekli kullanan bir yazarın hakem-dergi-editör’den oluşan modern bermuda şeytan üçgeninin derinliklerinden kurtulabileceğine pek ihtimal vermiyorum. Bunun sebebi, yukarıda adı geçen üçlünün, makaleyi okuyan kişilerin bildirilen sayı ve sonuçların gerçekten ne anlama geldiğini anladıklarından emin olmak istemeleridir. Bu sebeple de bazı açıkça belirtilmeyen, gizli kurallara uymanız beklenir.
Her gizli kural gibi, bu kurallar da elbette ülkeden ülkeye ve yayınlanan dile göre değişkenlik gösterecektir. Ancak genel kaideler açısından belirli bir stile sahip olmak ve her dilde onu takip etmek en doğrusudur. Günümüzde bilim, tarım devrimi sonrasında olduğu gibi tek başına yapılan gözlemler ve buluşlardan ibaret değildir. Halihazırda pahalı ve zorlu olan araştırmalar dünyanın dört bir yanında farklı araştırmacılar tarafından birbirlerini destekleyen ve devam ettiren şekilde yapılmaktadır. Bu sebeple de bilim çok dillidir. Bilim dilinin ne olduğu, hangi dilde makalelerin yayınlanması gerektiği gibi retorik tartışmalar yıllarca ülkemizde de devam etmiş olsa da, önemli olanın bildirilen dil değil içerik ve araştırmanın değeri olduğunu aklınızdan çıkarmayın. Bu nedenle, yayınların mümkün olan en fazla kişiye ulaşması ve en anlaşılır şekilde hazırlanması bir zaruriyettir. Muhtemelen kendi dilimizde yazdığımız bir makalenin 80 dilde tamı tamına yazdığımız anlamda otomatik olarak çevirileceği, cep telefonunuzun otomatik olarak konuşmanızı simultane olarak dönüştüreceği günler çok yakın. Ama yine de, o zamana kadar, bilim adına en fazla kişiye ulaşmak için yazılarınızı İngilizce olarak bir dergide yayınlayacağınızı, ya da uluslararası bir sempozyumda İngilizce bildireceğinizi düşünerek bu dilde sayısal verileri bildirmenin inceliklerinden bahsedeceğim.
Bazı temel bilgileri hatırlayalım
- Sürekli değişken: Ölçümle ifade edilen sayısal değişkenler. Grafiksel olarak gösterildiklerinde her sayıyı alabilecek, sadece sabit noktalarda birikmeyen veriler.
- Yaş (ama gün, saat, dakika düzeyinde ise), ağırlık (sadece kg olarak değil, g hatta mg cinsinden ölçüldüyse), boy (mesela metre değil de, cm hatta mm cinsinden ölçüldüğünde), CRP düzeyi gibi.
- Yaş, ağırlık, boy gibi ölçümler aslında sürekli olsalar da yıl, kg, metre gibi daha kaba ölçeklerle bildirildiklerinde ordinal (sıralı) değişkene dönüşürler. Ama normal dağıldıkları sürece (ki bu konuya ayrı bir yazıyla değineceğiz) yine de sürekli değişken gibi bildirmeye devam ederiz.
- Kategorik (nominal) değişken: Gruplarla ifade edilen ve her sayının aslında bir grubu ifade ettiği değişkenler.
- Cinsiyet (erkek/kadın), obezite durumu (obez/değil), HT varlığı (var/yok), San Fransisko Senkop Riski (Düşük/Orta/Yüksek), Travma mekanizması (düşme/ADTK/AİTK/ASY/diğer) vb gibi.
- Binom değişken: sadece 2 gruptan oluşan kategorik değişkenler. Cinsiyet (erkek/kadın), obezite durumu (obez/değil), HT varlığı (var/yok)
- Ordinal değişken: birbiri ardına mantıklı bir sıralamaya dayanan gruplandırılmış değişkenler. San Fransisko Senkop Riski (Düşük/Orta/Yüksek), eğitim durumu (ilk/orta/lise/üniversite), GKS (3/4/5/…/14/15) ya da GKS (hafif/orta/ağır) gibi
- Tip 1 hata: Belirlenen farkın şans eseri anlamlı bulunma ihtimali, alfa değeri.
- Tip 2 hata: Gerçekte fark olmasına rağmen bu farkın belirlenememe ihtimali.
- Güç: 1 – Tip 2 hata. Çalışmanın gerçekte var olan farkı belirleyebilme, yanlışlıkla fark yok dememe ihtimali.
Bazı temel matematiksel bilgileri de hatırlamakta fayda var
- Pay: Kesirli sayılarda üstteki sayı
- Payda: Kesirli sayılarda alttaki sayı
- Anlamlı basamak: Ondalık sayılarda virgülden sonraki basamak sayısı.
- Yuvarlama: Yuvarlama yapılırken basamakta sayı 4 ve altındaysa bir üst basamak aynı bırakılır, 5 ve üstündeyse 1 üste yuvarlanır.
- 22,4 » 22;
- 22,66 » 22,7;
- 110,445 » 111 gibi.
- Türkçe ve Fransızca’da ondalık sayılar virgül (,) ile binler basamakları nokta (.) ile ayrılır, yüzde ve para işaretleri sayının sonuna konulur. İngilizce’de ise ondalık sayılar nokta (.) ile binler basamakları virgül (,) ile ayrılır, yüzde ve para işaretleri sayının başına konulur. Türkçe’de %54,8 ve 115.500 TL, İngilizce yazarken 54.8% ve TL115,000 olarak belirtilmelidir.
Sayısal kesinlik
- Bildirdiğiniz tüm sayılar uygun kesinlik derecesiyle bildirilmelidir. Ortalama yaşam beklentisini 22,345 yıl olarak vermenin, 22 yıl olarak vermeye tercih edilmesini gerektirecek mantıklı ve pratik bir sebebi yoktur. Aksi gerekmedikçe ondalık sayılarda 2 anlamlı basamaktan fazlasını vermeye gerek yoktur.
- Sayısal veriler sunulurken yuvarlanmış olsa dahi analiz edilirken en ayrıntılı halleriyle analize dahil edilmelidir. Bölümde Duyarlılık ve Özgüllükle ilgili örnek hesaplamaları yaparken sayıları yuvarladığımızı farketmişsinizdir. Ancak olabilirlik olasılıklarını hesaplarken yuvarlanmış sayıları kullansaydık +LR 10,6 çıkacakken kesin sayıları kullandığımız için 11,4 olarak bildirdik.
- Klinik araştırmalarda bildirilen ondalık sayılarda 3 ya da daha fazla anlamlı basamak kullanmak nadir birkaç durum dışında tamamen gereksizdir. Örneğin, p değeri ne olursa olsun p<0,001’den daha ufak şekilde ifade etmenin genelde pek bir anlamı yoktur.
Sayısal Veri, Özetlenmesi ve Tanımlayıcı İstatistikler
Tüm çalışmalarda hastalardan (ya da deneklerden) elde edilen verilerin her hasta için tek tek bildirilmesi yerine çalışmada yer alan tüm grubun toplu bir değerini yansıtan tanımlayıcı istatistiklerinin verilmesi tercih edilir. Bunun sebebi 5000 tane hastanın tek tek kan basınçlarını vermenin pratik olmaması değil, aslında herhangi bir anlam ifade etmemesidir. Biz, çalışmaları, toplumdaki bir gerçeği tespit etmek amacıyla yaparız. Bu gerçek, 2 ilacın etkinlikleri arasındaki farkın büyüklüğü olabileceği gibi, belli bir hastalığa yakalananların beklenen ortalama sağkalım süresi, ya da diyabetin post-op yara enfeksiyonu riskini ne kadar artırdığı olabilir. Amaç, olabildiğinde toplumu yansıtan bir grup hastada tek tek yaptığımız ölçümleri biraraya getirerek toplumdaki hasta olmayan herhangi bir kişi için olasılıkları hesaplamaktır. Bu sebeple de bildireceğimiz sayılar ölçümleri yaptığımız çalışma grubumuzu temsil ettiği kadar (bundan sonra örneklem diyeceğim) aslında esasında bulmak istediğimiz toplumdaki asıl değer hakkında da fikir vermelidir.
Yukarıda da belirtiğimiz şekilde sürekli ve kategorik değişkenler için verileri nasıl özetleyeceğimizi daha ayrıntısıyla görelim:
Sürekli değişkenlerin bildirilmesi
Yaş, boy, ağırlık, CRP düzeyi gibi sürekli bir değişkeni bildirmek için mutlaka merkezi ağırlık ve dağılımlarını gösteren ölçütleri de bildirmelisiniz.
Değişken normal dağılıma uyuyorsa (az sonra bahsedeceğiz) ortalama ve standart sapması ile örneklemin tanımlayıcı istatistiği, ortalama ve %95 güven aralığı ile de toplumdaki kesinliği gösterilmekte olup, yerine göre her ikisi de verilmelidir. Tanımlayıcı istatistiklerde ortalama (ve standart sapma-SS) verilirken, karşılaştırmalarda ortalama (ve %95’lik güven aralığı-GA) verilmelidir.
- Ortalama, verilerin toplanıp veri sayısına bölünmesi ile hesaplanır.
- Standart sapma varyansın kareköküdür. Hesabına burada girmeyeceğim. Ancak her bir verinin ortalamadan ne kadar uzak olduğunun tek tek hesaplanması ve toplanması ile elde edilen bir çeşit veri olduğunu belirtelim. Dolayısıyla veri setinin ne kadar dağınık olduğunun göstergesidir. Standart sapmanın bizim için en önemli kısmı, verinin 2/3’ünün ortalamadan 1 SS uzaklıkta, %95’inin 2 SS uzaklıkta olmasıdır.
Normal dağılıma uymayan değişkenler için medyan ve interkuartil aralık (İKA [interquartile range=IQR]) verilmelidir.
- İnterkuartil aralık 25 ve 75. persentile karşılık gelen değerlerin kendileri (örneğin 45-75) ya da aralarındaki fark (mesela 30) olarak bildirilebilir.
- Bunun hesabında veri önce büyükten küçüğe doğru sıraya sokulur. Persent yüzdelik dilim anlamına gelir. Dolayısıyla 25. persentil %25’lik dilimdeki değer olarak düşünebiliriz. Eğer çalışmamız 100 vakalık ise 25., 40 vakalık ise 10., 200 vakalık ise 50. sıradaki değer 25. persentile karşılık gelir. Aynı şekilde 75., 30., ve 150. sıradaki değerler de 75. persentildeki değerdir. Dolayısıyla 25. ve 75. persentildeki değerler arasında çalışmamızdaki vakaların yarısı bulunur. Ya da vakaların %75’inin 25. persentildeki değerden büyük olduğunu söyleyebiliriz. Örneğin şu şekilde 18 vakadan oluşan bir veri setimiz olsun (mesela hastaların yaşları):
2 7 12 14 16 22 24 26 28 28 29 30 33 38 45 56 98 100
Sıraya dizili bu hastaların medyan yaşı kaçtır? Medyan, aslında 50. persentildir. Dolayısıyla en ortadaki vakanın değeri bizim medyan değerimizdir.
2 7 12 14 16 22 24 26 28 28 29 30 33 38 45 56 98 100
- 18 vakamız olduğundan ve bu sayı çift sayı olduğundan tam ortada kalan bir vaka yoktur. O zaman 9. ve 10. vakaların (yani 28 ve 28 değerlerinin) ortalamalarını alırız. Bu ortalama 28 olup, bu hasta grubunun medyan yaşını ya da 50. persentili gösterir.
- 25. persentile karşılık gelen noktada 16 değerini, 75. persentilde de 38 değerini görüyoruz. O zaman medyanı 28 olan ve interkuartil aralığı 16-38 ya da 22 olan bir çalışma grubumuz var.
- En küçük hastamız 2 en büyüğü 100 yaşında olup aralarındaki fark 98 yaştır. Bu da aralık (range) olarak ifade edilen dağılım ölçütüdür.
- Aralık (bu seride 98 yıl) vakaların nasıl dağıldığını sayısal olarak bize göstermekte yetersizdir. Vakaların hepsi 98 yıllık bir aralıkta yer alsa da yarısı sadece 22 (İKA) yıllık bir fark arasında yer almaktadır. Dahası 25 persentil olan 16 yaş ve medyan değer olan 28 yaş arasındaki 12 yaşlık aralıkta vakalarımızın dörtte biri, 75. persentil olan 38 ile medyan olan 28 yaş arasındaki 10 yaşlık kısımda da yine %25’i yer alıyor. En alt 25’lik ya da 1. çeyreklik dilimde 16-2 yaş yani 14 yaşlık aralıktaki bir hasta grubu varken, en üst dilimde 100-38 yani tam 62 yaşlık bir genişliğe sahip hastalar mevcuttur. Buna göre ilk 3 çeyrek grupta hastaların nispeten dengeli olarak dağıldığını (14, 12, 10 yıl) ama 4. çeyreğin dağılımı bozduğunu söyleyebiliriz (62 yıl). Buna göre bu dağılım normal ve dengeli olmaktan uzaktır.
- Eğer tüm verileri toplayıp 18 vaka sayısına bölersek de aritmetik ortalamayı elde etmiş oluruz. Bu değer tam olarak 33,78 yıldır. Tamamen normal şekilde dağılmış bir veride medyan ve ortalama değerler aynı olaaktır. Halbuki örneğimizde aralarında 5 yıllık bir fark vardır.
Normal dağılım Histogram adı verilen frekans grafikleri ile gösterilir
- Normal dağılım aşağıdaki 2 grafikte noktalı çizgilerle belirtildiği şekilde çan eğrisine benzer bir dağılım eğrisidir. Farklı bir yazı ile ayrıntısına girecek olsak da normal dağılımın en azından simetrik olması gerektiğini burada söyleyebiliriz. Simetrik olmayan veriler tek tarafa yatık bir dağılım gösterir ve normal dağılıma uymazlar. Normal dağılıma uymayan verilerin özetlenmesi ve istatistiksel analizlerde kullanılabilmeleri için ya dönüştürülmeleri (transformasyon) ya da parametrik olmayan testlerle karşılaştırılmaları gerekir. Ayrıca özetlenecekleri zaman normal dağılıma uyan verilerle aynı şekilde bildirilemezler.
- Aşağıdaki ilk grafiğin normal dağılıma uyduğunu ikincinin ise uymadığını rahatlıkla söyleyebiliriz.
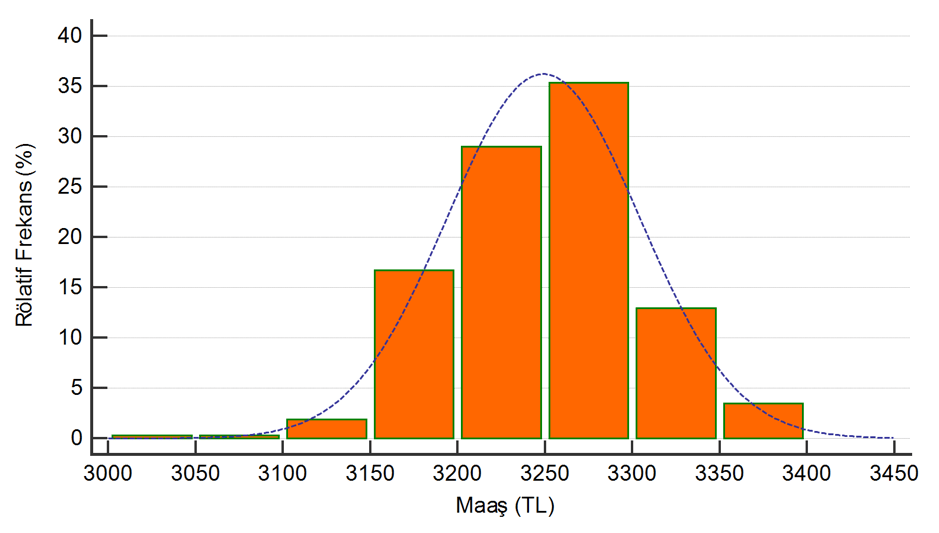
- İkinci grafik yukarıda verdiğimiz örneğe ait frekans grafiğidir. Her turuncu kutu belirlediğimiz aralıkta (burada 10 yıllık dilimler) kaçar vaka yer aldığını göstermektedir.
- Sayılar istenilen büyüklükte dilimler ile gruplanır. Her grupta kaç tane vaka olduğu sayılır. Bu sayılara frekans adı verilir. Bunların grafiksel gösterimi de histogramdır. Aşağıdaki grafikte kutuların boyutu yukarıda her dilim için saydığımız sayıları göstermektedir.
- Normal dağılımın simetrik ve çan eğrisine benzer şekilde olduğunu söylemiştik. Görsel açıdan aşağıdaki grafiğin normal olmadığını, bir ucunun uzun olduğunu söylebiliriz. Bu ucu bize göre ekranın sağında kalan kısımdır. Tıpkı tomografi ya da direk grafide olduğu gibi bizim sağımız görselin soludur. Dolayısıyla bu grafiğin sol ucu uzundur.
2 7 12 14 16 22 24 26 28 28 29 30 33 38 45 56 98 100
2 3 6 3 1 1 1 1

Normal dağılsalar da dağılmasalar da, sürekli değişkenlerin dağılımlarının grafiksel olarak gösteriminde klasik Tukey kutu-çizgi grafiği (box-plot) tercih edilir.
- Aşağıda gösterilen varyasyonunda en orta çizgi medyan, kutunun kenarları %25 ve %75 persentiller, yani kutunun tamamı interkuartil aralık, çizginin uçları da aşırı ve aykırı değerler dışındaki en düşük ve yüksek değerleri temsil etmektedir.
- Aykırı değer (outside value) interkuartil aralıktan (İKA), interkuartil aralığın 1,5 katından daha uzak değerler; aşırı değerler de İKA’dan İKA’nin 3 katından daha uzak değerler olarak tanımlanır.
- Aykırı değerler (şekildeki gibi) yuvarlak ile, aşırı değerler ise yıldız ile gösterilir.

- Yukarıdaki örneğimizi devam ettirdiğimizde aşağıdaki box-plot grafiğini çizebiliriz. Medyan 28, 25p 16, 75p 38 değerli ortadaki çizgi ve kutunun kenarlarını sınırlamaktadır. İKA 22 olduğuna göre medyan değer olan 28’e İKA’nın 1,5 katı olan 33’den daha uzak değerler alt sınırda -5 üst sınırda ise 61’den büyük değerler olmalıdır. -5’den küçük yaş olmayacağından alt sınırda aykırı değerimiz yoktur ve alt çentik aykırı değerlerden sonraki en düşük değer olan, serinin en küçük değeri olan 2’yi göstermektedir. Üst sınırda ise 61’den büyük 2 değer vardır 98 ve 100. Bunlar yuvarlar işaretlerle belirtildikten sonra geri kalanlar içindeki en büyük değer olan 56’dan da üst çizgi çizilmiş ve box-plot grafiği tamamlanmıştır. Bu grafik dağılım açısından bize çok daha fazla bilgi vermektedir.
Paket program ile döküm alınması
- Yukarıda anlattıklarımızın hepsini aslında bir istatistik paket programı (burada medcalc kullanılmıştır) size tek bir tıklama ile aşağıdaki gibi bir döküm halinde verecektir. Ama bunu başta söyleseydim hiçbiriniz bu kısımları okumazdınız.
- Yukarıda nasıl hesaplandığından bahsetmediğimiz (ve hiçbir zaman da bahsetmeyeceğimiz) en önemli veriler ise bu dökümde gördüğünüz
- %95 güven aralıkları (medcalc ile medyan ve İKA’lar için de %95 güven aralığı hesaplandığına dikkat edin) ve
- Shapiro-Wilk normalite testi sonucudur.
- %95 güven aralığını bir örnek ile açıklayalım: Metastatik kolon kanseri sonrası 1. basamak A kemoterapisi sonrası progresyonsuz sağkalım süresi 40 hastalık çalışma örneklemimizde medyan 16 ay olabilir. Ama esas ilgilendiğimiz ve merak ettiğimiz değer bizim 40 hastamız değil, Türkiye’deki tüm metastatik kolon kanseri sonrası 1. basamak A kemoterapisi alan hastaların medyan progresyonsuz sağkalım süresidir. Eğer 40 kişilik 100 farklı örnek ile aynı çalışmayı tekrarlarsak, normal dağılan bir örnek için 95 keresinde progresyonsuz sağkalım süresi ortalamasının hangi 2 değer arasında olabileceğini hesaplayabiliriz. Buna %95 güven aralığı diyoruz. Böylece çalışma örneklemi yerine toplumdaki gerçeği tahmin etme gücümüzü bir şekilde okura da belirtmiş oluyoruz.
- Bu dökümde de rahatlıkla görüleceği üzere medyan 28, 25 ve 75. persentiller de 16 ve 38’dir. Shapiro-Wilk testi bu veri setinin dağılımını normal dağılım ile karşılaştırmış ve aralarındaki farkın istatistiksel olarak anlamlı olduğunu göstermiştir (P=0.0021).
Tüm bu öğrendiklerimizle tanımlayıcı verileri nasıl bildireceğimizi toparlayalım:
- Normal dağılan sürekli bir değişkenin tanımlayıcı istatistiği verilirken “Ortalama (SS) CRP düzeyi 12,8 (4,2) mg/dl’dir” şeklinde ifade edilmeli, öngörülen bu ortalamanın toplumdaki kesinliği ifade edilirken ise “Ortalama (%95 GA) CRP düzeyi 12,8 (%95 GA: 11,98;13,62)” şeklinde belirtilmelidir.
- İlk ifade örneklemin (yani çalışmayı yaptığımız grubun) ortalamasını ve değişkenliğini gösterirken, ikinci ifade aynı çalışmanın 100 kez farklı örneklemlerde yapılmış olması durumunda 95 kez ortalamanın hangi aralıkta olacağını gösterir.
- Ortalama ± SS (%95 GA) şeklindeki ifade ise her ikisini birden kısa yoldan göstermek için kullanılsa da karışıklık yaratacağından tablolar gibi yer kısıtı olan yerler dışında öncelikli olarak tercih edilmemelidir. Edilecekse bile her sayının hangi anlama geldiği en azından metot kısmında mutlaka belirtilmelidir.
- Normal dağılmayan değişkenler bildirilirken “antikor titresi medyan (interkuartil aralık-İKA) değeri 100 ng/ml (61-159 ng(ml) olup 25 ile 347 ng/ml arasında değişmektedir” şeklinde ifade edilmeli ve medyan ile İKA gibi dağılım ölçütleri bildirilmelidir.
Sürekli değişkenlerin bildiriminde dikkat edilecek hususlar
Sürekli değişkenleri, ortalama ve ortalamanın standart hatası (standard error of mean) ile göstermeyin.
- Ortalamanın standart hatası (SH [Standard Error of Mean = SEM]) tahmini toplum ortalamasının keskinliğinin bir ölçütüdür.
- Standart Sapma (SS [Standard Deviation = SD]) ise örneklem ortalamasının çevresindeki değişkenliğin bir ölçütüdür.
- SS tanımlayıcı bir istatistiksel ölçüt iken SH değildir.
- SH, SS’den daha küçük olduğundan bazı yazarlar bu sayıyı ortalamalar ile verme eğiliminde olup, bu yaklaşım tamamen hatalıdır.
- Bir örneklemden elde ettiğimiz ortalamadan toplumun ortalamasını öngörmeye çalışırken %95’lik güven aralığı ile beraber veririz. İşte, ortalamanın toplumdaki güven aralığını bulurken, normal dağılımın %97,5 ve %2,5 kuartillerine denk gelecek şekilde standart hatanın 1,96 katını ortalamaya ekleyerek buluruz.
Değişkenlerin tanımlayıcı istatistiklerinde Ortalama (SS) şeklindeki gösterimi sadece normal ve yaklaşık olarak normal dağılıma sahip örneklemlerde kullanın. Normal dağılmayan örneklemlerde tanımlayıcı istatistikleri medyan ve İKA ile ifade edin.
- Siz bir veriyi ortalama (SS) olarak bildirdiğinizde, okuyucular bu değişkenin normal dağıldığını kabul ederek vakaların %68’inin ortalamanın 1 SS kadar altı ve üstü arasında olduğunu, 2 SS kadar uzağındaki kısımda %95’inin ve 3 SS kadar uzağındaki aralıkta da %99’unun yer aldığını kabul ederler.
- Bu, Gauss dağılımı ya da Çan eğrisi şeklindeki normal dağılımın standart özelliğidir.
- Poisson ya da ki-kare dağılımı gibi dağılımlar da ortalama (SS) ile ifade edilebilse de, bu dağılımlar genel okuyucu tarafından bilinmez ve anlaşılmaz. Dolayısıyla da normal dağılıma uyan haller dışında sadece medyan ve İKA bildirilmelidir.
Ortalama (SS), kaynaklandığı veriden en fazla 1 ondalık basamak daha fazla basamak içermelidir.
- Eğer 18, 21, 33, 35, 42 gibi sayılardan oluşan CRP değişkeni bildiriliyorsa ortalama (SS) 29,8 (10,0) şeklinde ya da ortalama (%95 GA) 29,8 (17,3; 42,3) şeklinde ifade edilmeli ve daha fazla basamak eklenmemelidir.
Negatif değerlerin olmadığı bir değişkende, ortalamanın yarısından daha büyük bir SS varsa normal dağılım yoktur ve medyan (İKA) ile bildirilmelidir.
- Ortalama (SS) değerleri 35,0 (24,3) şeklinde olan bir değişken bildirildiğinde okuyucu vakaların %95’inin değerinin 2 SS aralığında olacağını hesaplayacaktır (bu değer %95’lik güven aralığı değildir, örneklemdeki vakaların %95’inin değerlerinin hangi aralıkta olduğudur).
- Hesaplama yaptığımızda vakaların %95’inin sahip olduğu değerin -13 ile 83 arasında olacağını görebilirsiniz. Eğer bu değişken negatif değerler alamayan bir değişkense dağılım normal olamaz. Bu sebeple de SS ortalamanın yarısından büyük, ya da 2 SS en fazla ortalama kadar olan değerlerde bu şekilde gösterim uygundur. Bunun dışındaki durumlarda hakemler ve okuyucular normal dağılmayan bir değişkeni ortalama ile verdiğinizi hemen fark edeceklerdir.
Ortalama (SS) ifade ederken ± işaretini kullanmayın.
- Tanım gereği zaten SS ortalamanın her iki kısmında simetrik olarak vakaların dağılımının göstergesidir, ± işareti ile gösterilmesi gereksizdir.
- Ayrıca ± işaretinden sonra verilen değerin SS mi SH mi yoksa %95 GA mı olduğu belirtilmediği sürece kesin olmayıp karışıklık yaratacaktır.
Çıkarımlar ve güven aralıkları
Hem örneklemin hem de popülasyonun tüm birincil karşılaştırmalarında sonucun anlamlı olup olmamasından bağımsız bir şekilde %95 güven aralıkları verilmelidir.
- Eğer iki ortalama birbiriyle karşılaştırılıyorsa en doğru gösterim ortalamalar arasındaki fark ve bu farkın %95 güven aralığının verilmesidir.
- Örneğin, “X ilacı kan basıncını ortalama 8 mmHg (%95 GA: 2 ila 14 mmHg) azaltmıştır”. Böyle bir gösterimde p değerine gerek olmayıp, çoğu A sınıfı dergi bu şekilde gösterimlerde p değerini istememektedir.
Grup ortalamaları arasındaki farkın (ya da aynı grubun ardışık ölçümleri arasındaki farkın) %95 güven aralığı 0 değerinden geçmediği (içermediği) sürece aradaki fark p değeri en fazla 0,05 olacak şekilde istatistiksel olarak anlamlıdır.
%95 GA odds oranı (OR) ya da risk oranına (RR) ait ise, 1 değerinden geçmediği (içermediği) sürece aradaki fark p değeri en fazla 0,05 olacak şekilde istatistiksel olarak anlamlıdır.
Kategorik verilerin bildirilmesinde dikkat edilecek hususlar
Yüzdeleri bildirirken mutlaka parantez içinde pay ve payda değerlerini de vermelisiniz
- %25 (650/2598), %33 (90 hastadan 30’u) veya 16 tavşanın 12’si (%75) gibi.
Yazdığınız yüzdelerin payda kısmında hangi sayıyı kullandığınızı mutlaka tekrar tekrar kontrol edin.
- Örneğin, “1000 hastanın 500’ü erkek (%50) olup, bu 500 erkeğin 250’sinde KAH (%50) mevcuttu.” önermesinde aslında toplam örneklemin 250/1000, %25’i hem erkek hem de KAH hastasıdır.
Örneklem boyutunuz 100’ün altındaysa yüzdeleri tam sayı olarak, 100’ün üstündeyse 1 ondalık basamak ile bildirin. Eğer 20’den az hasta varsa yüzde yerine sayı verin.
- “Bu çalışmadaki hastaların %33’ü şifa ile, %33’ü sekelli olarak taburcu edilmiş olup diğer hasta çalışmaya katılmaya onam vermemiştir.” gibi bir cümle hakemlerinizi çok eğlendirse de yazınızın kabulüne pek katkı sağlayacağını söyleyemeyiz.
Yüzdesel değişiklikleri rölatif olarak bildirmek istiyorsanız daima ilk değere göre bildirmelisiniz.
- Kullanacağınız formül [(son değer – ilk değer)/ilk değer] şeklinde olmalıdır. Eğer elde ettiğiniz sayı negatif yani azalma yönündeyse sayının önündeki negatif işaretini atıp hesapladığınız sayısı azalma olarak bildirin. Mümkünse de hiç rölatif bildirim yapmayın.
- Kan basıncının 100’den 120’ye çıkması %20 artış ifade ederken, 100’den 80’e düşmesi %20 azalma ifade eder.
Oran, orantı ve yüzdelerin payda kısmında ne ifade edildiğini mutlaka açıklayın.
Örneklem büyüklüğü grafik kullanılmasını haklı çıkaracak kadar büyük olmadığı sürece kategorik değişkenleri metinde özetleyin ve grafik kullanmayın.
- Sadece yüzdesel veri ifade eden pay ya da bar grafikleri yazınızı ucuz gösterecektir.
Sürekli bir değişkeni ordinal (sıralı) kategorilere böldüyseniz, eşik değerleri niye seçtiğinizin sebebini ve bu eşik değerlerin neler olduğunu mutlaka belirtin.
- En sık yapılan hatalardan biri yaş gibi sürekli bir değişkeni 10’arlı yaş gruplarına bölerek kategoriler halinde bildirmektir. Epidemiyolojik çalışmalarda belki tarihsel anlamı ve eski verilerle karşılaştırılabilirliği açısından anlamı olsa da, özellikle klinik araştırmalarda tam tersine veri kaybına yol açan hatalı bir uygulamadır. Mümkünse sürekli bir değişkeni asla kategorik hale getirmeyin.
Ordinal değişkenlerin tanımlayıcı istatistiklerinde sürekli değişkenmiş gibi ortalama (SS) bildirmeyin.
- Pnömoni Ağırlık Skoru 1=hafif, 2=orta, 3=ağır, 4=şiddetli olarak kodlanmış ise ortalama pnömoni ağırlık skoru 2,3 olarak ASLA bildirilemez. Her ne kadar bu veriler sıralı olsa da, sıraların arasındaki uzaklık eş değildir.
- Aynı şekilde Glasgow Koma Skoru (GKS), Injury Severity Skoru (ISS) gibi skorların bildirimlerinde her kategorinin frekansı ve modal skor (yani en fazla skoru alan kategori) bildirimi daha uygundur. Ordinal olsalar da normal dağılan 10 ya da 7 üzerinden memnuniyet seviyesi ya da yaş gibi (aslında yaşı yıl olarak aldığımızda sürekli değil ordinal bir değişkendir, ara değerler yoktur) değişkenlerin ortalamalarının bildirilmesi daha kabul edilebilir bir uygulamadır.
Hemen akabinde gelecek bu serinin 2. yazısında bildirim şekillerinin daha ayrıntılarına ineceğiz.